In the previous post of this series unveiling the relationship between UFO sightings and population, we crossed the threshold of normality underpinning linear models to construct a generalised linear model based on the more theoretically satisfying Poisson distribution.
On inspection, however, this model revealed itself to be less well suited to the data than we had, in our tragic ignorance, hoped. While it appeared, on visual inspection, to capture some features of the data, the predictive posterior density plot demonstrated that it still fell short of addressing the subtleties of the original.
In this post, we will seek to overcome this sad lack in two ways: firstly, we will subject our models to pitiless mathematical scrutiny to assess their ability to describe the data. With our eyes irrevocably opened to these techniques, we will construct an ever more complex armillary with which to approach the unknowable truth.
Critical Omissions of Information
Our previous post showed the different fit of the Poisson model to the data from the simple Gaussian linear model. When presented with a grim array of potential simulacra, however, it is crucial to have reliable and quantitative mechanisms to select amongst them.
The eldritch procedure most suited to this purpose, model selection, in our framework, draws on information criteria that express the relative effectiveness of models at creating sad mockeries of the original data. The original and most well-known such criterion is the Akaike Information Criterion, which has, in turn, spawned a multitude of successors applicable in different situations and with different properties. Here, we will make use of Leave-One-Out Cross Validation (LOO-CV)1 as the most applicable to the style of model and set of techniques applied here.
It is important to reiterate that these approaches do not speak to an absolute underlying truth; information criteria allow us to choose between models, assessing which has most closely assimilated the madness and chaos of the data. For LOO-CV, this results in an expected log predictive density (elpd) for each model. The model with the lowest elpd is the least-warped mirror of reality amongst those we subject to scrutiny.
There are many fragile subtleties to model selection, of which we will mention only two here. Firstly, in general, the greater the number of predictors or variables incorporated into a model, the more closely it will be able to mimic the original data. This is problematic, in that a model can become overfit to the original data and thus be unable to represent previously unseen data accurately — it learns to mimic the form of the observed data at the expense of uncovering its underlying reality. The LOO-CV technique avoids this trap by, in effect, withholding data from the model to assess its ability to make accurate inferences on previously unseen data.
The second consideration in model selection is that the information criteria scores of models, such as (elpd) in LOO-CV, are subject to standard error in their assessment; the score itself is not a perfect metric of model performance, but a cunning approximation. As such we will only consider one model to have outperformed its competitors if the difference in their relative elpd is several times greater than this standard error.
With this understanding in hand, we can now ruthlessly quantify the effectiveness of the Gaussian linear model against the Poisson generalised linear model.
Gaussian vs. the Poisson
The original model presented before our subsequent descent into horror was a simple linear Gaussian, produced through use of ggplot2‘s geom_smooth function. To compare this meaningfully against the Poisson model of the previous post, we must now recreate this model using the, now hideously familar, tools of Bayesian modelling with Stan.
Show Gaussian model specification code.
population_model_normal.stan
[code language=”c”]
data {
// Number of rows (observations)
int<lower=1> observations;
// Predictor (population of state)
vector[ observations ] population;
log_lik[n] = normal_lpdf( counts[n] | a + population[n]*b, sigma );
counts_pred[n] = normal_rng( a + population[n]*b, sigma );
}
}
[/code]
With both models straining in their different directions towards the light, we apply LOO-CV cross validation to assess their effectiveness at predicting the data.
Show LOO-CV comparison code.
LOO-CV R-code snippet. Full code is at the end of this post.
[code language=”R”]
> compare( loo_normal, loo_poisson )
elpd_diff se
-8576.1 712.5
The information criterion shows that the complexity of the Poisson model does not, in fact, produce a more effective model than the false serenity of the Gaussian2. The negative elpd_diff of the compare function supports the first of the two models, and the magnitude being over twelve times greater than the standard error leaves little doubt that the difference is significant. We must, it seems, look further.
With these techniques for selecting between models in hand, then, we can move on to constructing ever more complex attempts to dispel the darkness.
Trials without End
The Poisson distribution, whilst appropriate for many forms of count data, suffers from fundamental limits to its understanding. The single parameter of the Poisson, \(\lambda\), enforces that the mean and variance of the data are equal. When such comforting falsehoods wither in the pale light of reality, we must move beyond the gentle chains in which the Poisson binds us.
The next horrific evolution, then, is the negative binomial distribution, which similarly speaks to count data, but presents a dispersion parameter (\(\phi\)) that allows the variance to exceed the mean3.
With our arcane theoretical library suitably expanded, we can now transplant the still-beating Poisson heart of our earlier generalised linear model with the more complex machinery of the negative binomial:
As with the Poisson, our negative binomial generalised linear model employs a log link function to transform the linear predictor. The Stan code for this model is given below.
// Center and scale the predictor
vector[ observations ] population;
population = ( population_raw – mean( population_raw ) ) / sd( population_raw );
}
parameters {
// Negative binomial dispersion parameter
real phi;
// Intercept
real a;
// Slope
real b;
}
transformed parameters {
vector<lower=0>[observations] mu;
mu = a + b*population;
}
model {
// Priors
a ~ normal( 0, 1 );
b ~ normal( 0, 1 );
phi ~ cauchy( 0, 5 );
// Model
// Uses the log version of the neg_binomial_2 to avoid
// manual exponentiation of the linear predictor.
// (This avoids numerical problems in the calculations.)
counts ~ neg_binomial_2_log( mu, phi );
With this model fit, we can compare its whispered falsehoods against both the original linear Gaussian model and the Poisson GLM:
Show LOO-CV comparison code.
Code snippet for calculating the LOO-CV elpd for three models. The full R code for building and comparing all models is listed at the end of this post.
> compare( loo_poisson, loo_negbinom )
elpd_diff se
8880.8 721.9
With the first comparison, it is clear that the sinuous flexibility offered by the dispersion parameter, \(\phi\), of the negative binomial allows that model to mould itself much more effectively to the data than the Poisson. The elpd_diff score is positive, indicating that the second of the two compared models is favoured; the difference is over twelve times the standard error, giving us confidence that the negative binomial model is meaningfully more effective than the Poisson.
Whilst superior to the Poisson, does this adaptive capacity allow the negative binomial model to render the naïve Gaussian linear model obsolete?
> compare( loo_normal, loo_negbinom )
elpd_diff se
304.7 30.9
The negative binomial model subsumes the Gaussian with little effort. The elpd_diff is almost ten times the standard error in favour of the negative binomial GLM, giving us confidence in choosing it. From here on, we will rely on the negative binomial as the core of our schemes.
Overlapping Realities
The improvements we have seen with the negative binomial model allow us to discard the Gaussian and Poisson models with confidence. It is not, however, sufficient to fill the gaping void induced by our belief that the sightings of abnormal aerial phenomena in differing US states vary differently with their human population.
To address this question we must ascertain whether allowing our models to unpick the individual influence of states will improve their predictive ability. This, in turn, will lead us into the gnostic insanity of hierarchical models, in which we group predictors in our models to account for their shadowy underlying structures.
Limpid Pools
The first step on this path is to allow part of the linear function underpinning our model, specifically the intercept value, \(\alpha\), to vary between different US states. In a simple linear model, this causes the line of best fit for each state to meet the y-axis at a different point, whilst maintaining a constant slope for all states. In such a model, the result is a set of parallel lines of fit, rather than a single global truth.
This varying intercept can describe a range of possible phenomena for which the rate of change remains constant, but the baseline value varies. In such hierarchical models we employ a concept known as partial pooling to extract as much forbidden knowledge from the reluctant data as possible.
A set of entirely separate models, such as the per-state set of linear regressions presented in the first post of this series, employs a no pooling approach: the data of each state is treated separately, with an entirely different model fit to each. This certainly considers the uniqueness of each state, but cannot benefit from insights drawn from the broader range of data we have available, which we may reasonably assume to have some relevance.
By contrast, the global Gaussian, Poisson, and negative binomial models presented so far represent complete pooling, in which the entire set of data is considered a formless, protean amalgam without meaningful structure. This mindless, groping approach causes the unique features of each state to be lost amongst the anarchy and chaos.
A partial pooling approach instead builds a global mean intercept value across the dataset, but allows the intercept value for each individual state to deviate according to a governing probability distribution. This both accounts for the individuality of each group of observations, in our case the state, but also draws on the accumulated wisdom of the whole.
We now construct a partially-pooled varying intercept model, in which the parameters and observations for each US state in our dataset is individually indexed:
Note that the intercept parameter, \(\alpha\), in the second line is now indexed by the state, represented here by the subscript \(i\). The slope parameter, \(\beta\), remains constant across all states.
This model can be rendered in Stan code as follows:
> compare( loo_negbinom, loo_negbinom_var_intercept )
elpd_diff se
363.2 28.8
Our transcendent journey from the statistical primordial ooze continues: the varying intercept model is favoured over the completely-pooled model by a significant margin.
Sacred Geometry
Now that our minds have apprehended a startling glimpse of the implications of the varying intercept model, it is natural to consider taking a further terrible step and allowing both the slope and the intercept to vary4.
With both the intercept and slope of the underlying linear predictor varying, an additional complexity raises its head: can we safely assume that these parameters, the intercept and slope, vary independently of each other, or may there be arcane correlations between them? Do states with a higher intercept also experience a higher slope in general, or is the opposite the case? Without prior knowledge to the contrary, we must allow our model to determine these possible correlations, or we are needlessly throwing away potential information in our model.
For a varying slope and intercept model, therefore, we must now include a correlation matrix, \(\Omega\), between the parameters of the linear predictor for each state in our model. This correlation matrix, as with all parameters in a Bayesian framework, must be expressed with a prior distribution from which the model can begin its evaluation of the data.
This model has grown and gained a somewhat twisted complexity compared with the serene austerity of our earliest linear model. Despite this, each further step in the descent has followed its own perverse logic, and the progression should clear. The corresponding Stan code follows:
Show negative binomial varying intercept and slope model specification code.
The ultimate test of our faith, then, is whether the added complexity of the partially-pooled varying slope, varying intercept model is justified. Once again, we turn to the ruthless judgement of the LOO-CV:
Show LOO-CV comparison code.
Code snippet for calculating the LOO-CV elpd. The full R code for building and comparing all models in this post is listed at the end.
[code language=”R”]
…
log_lik_negbinom_var_intercept_slope <- extract_log_lik(fit_ufo_pop_negbinom_var_intercept_slope, merge_chains = FALSE)
r_eff_negbinom_var_intercept_slope <- relative_eff(exp(log_lik_negbinom_var_intercept_slope))
loo_negbinom_var_intercept_slope <- loo(log_lik_negbinom_var_intercept_slope, r_eff = r_eff_negbinom_var_intercept_slope, cores = 2)
…
[/code]
> compare( loo_negbinom_var_intercept, loo_negbinom_var_intercept_slope )
elpd_diff se
13.3 2.4
In this final step we can see that our labours in the arcane have been rewarded. The final model is once again a significant improvement over its simpler relatives. Whilst the potential for deeper and more perfect models never ends, we will settle for now on this.
Mortal Consequences
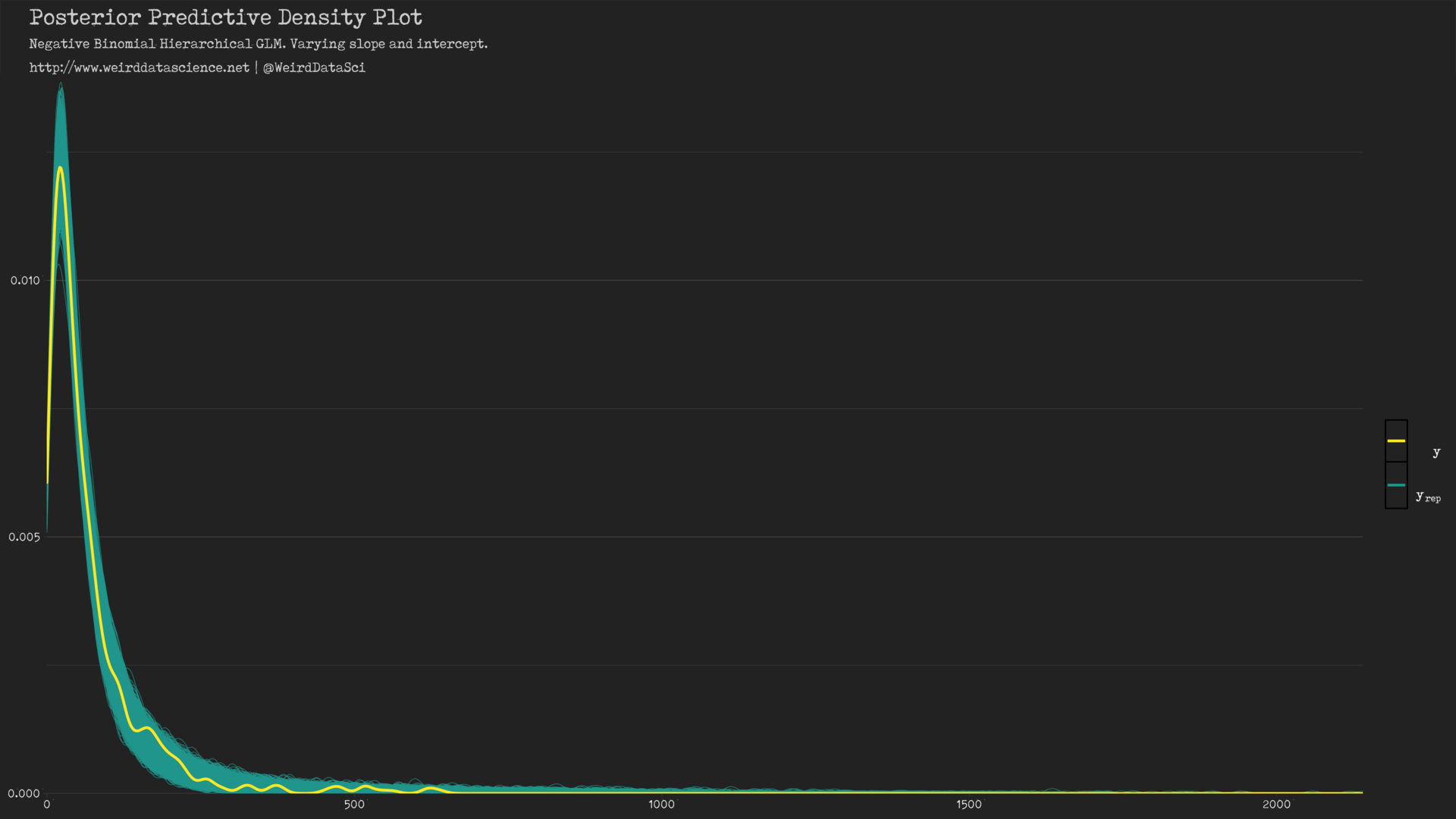
With our final model built, we can now begin to examine its mortifying implications. We will leave the majority of the subjective analysis for the next, and final, post in this series. For now, however, we can reinforce our quantitative analysis with visual assessment of the posterior predictive distribution output of our final model.
Posterior predictive density plot of varying intercept, varying slope negative binomial GLM of UFO sightings. (PDF Version)
Show posterior predictive plotting code.
bayes_plots.r
(Includes code to generate traceplot and posterior predictive distribution plot.)
[code language=”R”]
# (Visualisations only produced for varying slope/intercept model, as a result
# of LOO checking.
# Bayesplot needs to be told which theme to use as a default.
theme_set( theme_weird() )
# Read the fitted model
fit_ufo_pop_negbinom_var_intercept_slope <-
readRDS( "work/fit_ufo_pop_negbinom_var_intercept_slope.rds" )
## Model checking visualisations
# Extract posterior estimates from the fit (from the generated quantities of the stan model)
counts_pred_negbinom_var_intercept_slope <- as.matrix( fit_ufo_pop_negbinom_var_intercept_slope, pars = "counts_pred" )
# First, as always, a traceplot
tp <-
traceplot(
fit_ufo_pop_negbinom_var_intercept_slope,
pars = c("pop_intercept", "pop_slope", "phi" ),
ncol=1 ) +
scale_colour_viridis_d( name="Chain", direction=-1 ) +
theme_weird()
In comparison with earlier attempts, the varying intercept and slope model visibly captures the overall shape of the distribution with terrifying ease. As our wary confidence mounts in the mindless automaton we have fashioned, we can now examine its predictive ability on our original data.
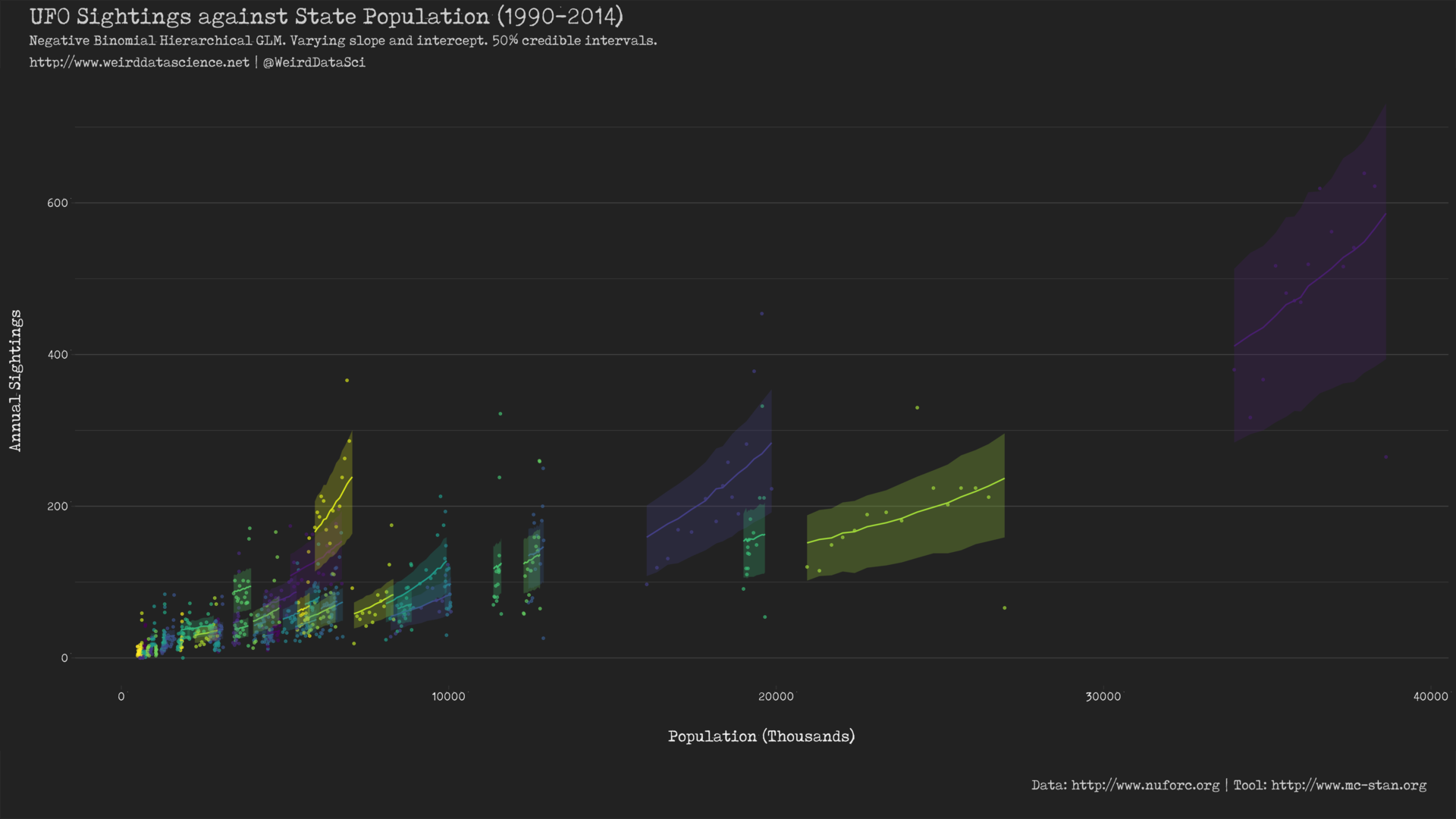
Varying intercept and slope negative binomial GLM of UFO sightings against population. (PDF Version)
Show negative binomial varying intercept and slope plot code.
# Plots, posterior predictive checking, LOO
theme_set( theme_weird() )
## Model checking visualisations
# Extract posterior estimates from the fit (from the generated quantities of the stan model)
counts_pred_negbinom_var_intercept_slope <- as.matrix( fit_ufo_pop_negbinom_var_intercept_slope, pars = "counts_pred" )
## Create per-state predictive fit plots
# Convert fitted model (stanfit) object to a tibble
fit_tbl <-
summary(fit_ufo_pop_negbinom_var_intercept_slope)$summary %>%
as.data.frame() %>%
mutate(variable = rownames(.)) %>%
select(variable, everything()) %>%
as_tibble()
The purpose of our endeavours is to show whether or not the frequency of extraterrestrial visitations is merely a sad reflection of the number of unsuspecting humans living in each state. After seemingly endless cryptic calculations, our statistical machinery implies that there are deeper mysteries here: allowing the relationship between sightings and the underlying linear predictors to vary by state more perfectly predicts the data. There are clearly other, hidden, factors in play.
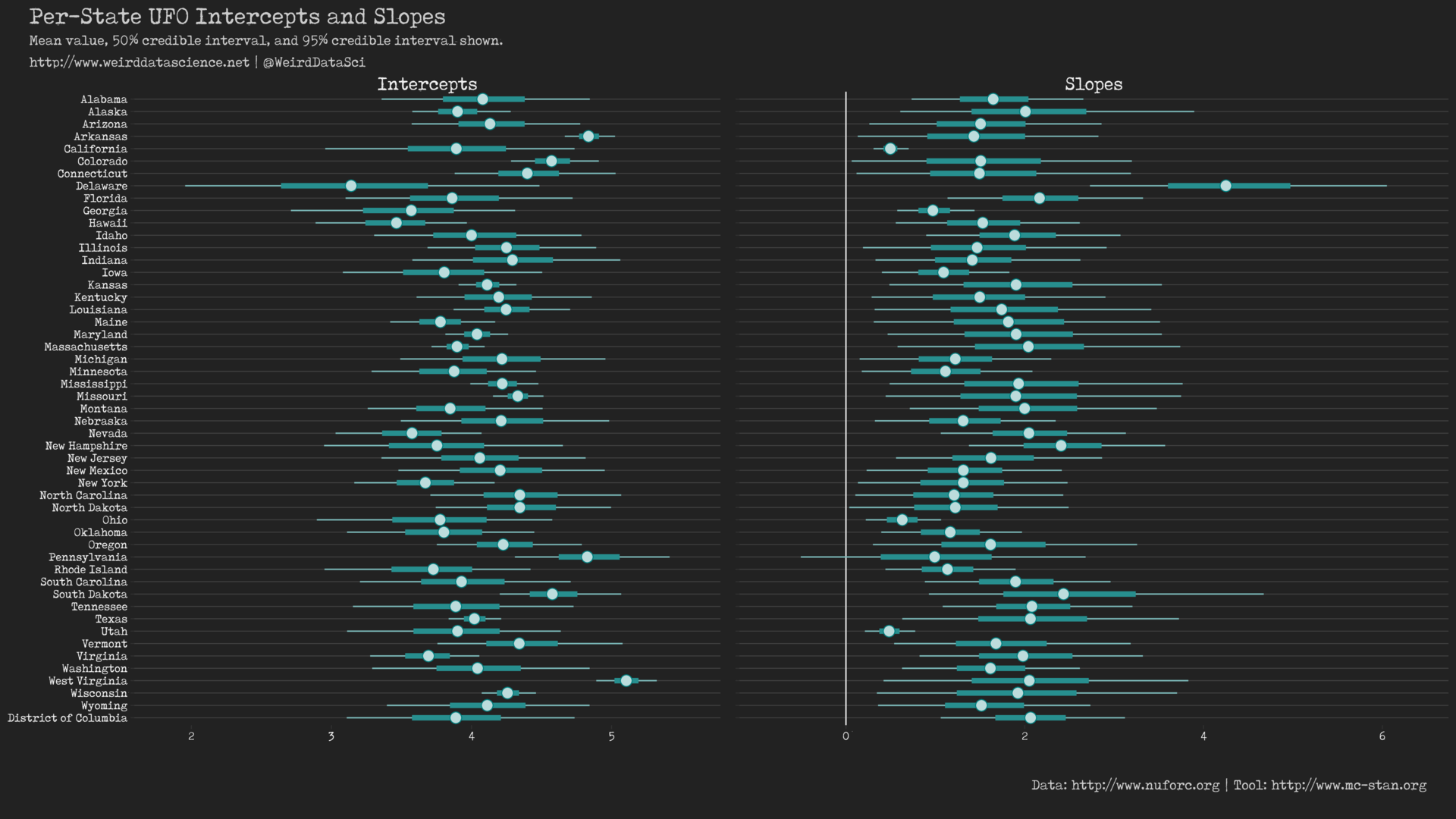
More than that, however, our final model allows us to quantify these differences. We can now retrieve from the very bowels of our inferential process the per-state distribution of paremeters for both the slope and intercept of the linear predictor.
Varying slope and intercept negative binomial GLM parameter plot for UFO sightings model. (PDF Version)
# Plots, posterior predictive checking, LOO
theme_set( theme_weird() )
# Use teal colour scheme
color_scheme_set( "teal")
## Model checking visualisations
# Extract posterior estimates from the fit (from the generated quantities of the stan model)
counts_pred_negbinom_var_intercept_slope <- as.matrix( fit_ufo_pop_negbinom_var_intercept_slope, pars = "counts_pred" )
# US state data
us_state_factors <-
levels( factor( ufo_population_sightings$state ) )
# US state names for nice plotting
# Data: <https://www.50states.com/abbreviations.htm>
state_code_data <-
read_csv( file="data/us_states.csv" ) %>%
filter( code %in% us_state_factors )
# Rename variables back to state names
posterior_intercepts <-
as.data.frame( fit_ufo_pop_negbinom_var_intercept_slope ) %>%
as_tibble %>%
select(starts_with(‘state_intercept’) ) %>%
rename_all( ~us_state_factors ) %>%
rename_all( ~extract2( state_code_data, "us_state" ) )
# Rename variables back to state names
posterior_slopes <-
as.data.frame( fit_ufo_pop_negbinom_var_intercept_slope ) %>%
as_tibble %>%
select(starts_with(‘state_slope’) ) %>%
rename_all( ~us_state_factors ) %>%
rename_all( ~extract2( state_code_data, "us_state" ) )
# Posterior draws combined
posterior_slopes_long <-
posterior_slopes %>%
gather( value = "slope" )
posterior_intercepts_long <-
posterior_intercepts %>%
gather( value = "intercept" )
# Interval plots (slope and intervals)
# Plot intercept parameters for varying intercept and slope model
gp_intercept <-
mcmc_intervals( posterior_intercepts ) +
ggtitle( "Intercepts" ) +
theme_weird()
# Plot slope parameters for varying intercept and slope model
# (Remove y-axis labels as this will be aligned with the intercept plot.)
gp_slope <-
mcmc_intervals( posterior_slopes ) +
ggtitle( "Slopes" ) +
theme_weird() +
theme(
axis.text.y = element_blank()
)
It is important to note that, while we are still referring to the \(\alpha\) and \(\beta\) parameters as the slope and intercept, their interpretation is more complex in a generalised linear model with a \(\log\) link function than in the simple linear model. For now, however, this diagram is sufficient to show that the horror visited on innocent lives by our interstellar visitors is not purely arbitrary, but depends at least in part on geographical location.
With this malign inferential process finally complete we will turn, in the next post, to a trembling interpretation of the model and its dark implications for our collective future.
Model Fitting and Comparison Code Listing
Show full model fitting and LOO-CV comparison code.
This code fits the range of models developed in this series, relying on the individual Stan source code files, and runs the LOO-CV comparisons discussed in this post.
This is perhaps not entirely surprising, based on our belief from the first post of this series that we should consider sightings at the state level rather than globally. With over fifty individual count processes fused into an amorphous mass, it is not entirely surprising that the Gaussian is a better approximation to the data.
There are several parameterisations of the negative binomial used for different applications. The distribution itself is often characterised as representing the number of binary trials, such as a coin flip, required before a given result, such as a number of heads, is achieved. The parameterisation we use here is a common way to represent overdispersed Poisson data.
One can build varying slope models with a fixed intercept, but we will not approach that horror here.
Glad you liked them! Using Stan is its own reward. 🙂
I actually have a new series of posts in preparation — I was coincidentally looking at them this weekend to get the code tidied up written up into posts. (The pandemic pulled away any spare capacity I had for this work, and it’s been hard to get back into it. This kind of comment is exactly the inspiration I need!)


Looking forward to the next post in this series.
Glad you’re enjoying them!
Excellent series of posts you have made … special kudos for using Stan!
Glad you liked them! Using Stan is its own reward. 🙂
I actually have a new series of posts in preparation — I was coincidentally looking at them this weekend to get the code tidied up written up into posts. (The pandemic pulled away any spare capacity I had for this work, and it’s been hard to get back into it. This kind of comment is exactly the inspiration I need!)